


PhD Work: Design
Contents
- A Domain Ontology for a NLQS
- Dataflow for a NLQS
- Visualizing Ontologies
- Ontology and RDF Data Files Map
- NLP Systems
- An Ontology for Representing User-Controlled Thesauruses
- Datastores
Entries
<< Previous Entry | Next Entry >>
6. An Ontology for Representing User-Controlled Thesauruses
One of the most crucial parts of an NL querying system is to be ability to map words and lexical concepts determined by the NLP to concepts that have been defined in the knowledge base. In the diagram in Section 4 (Ontology and RDF Data File Map), two components are defined by the designer. The first is the Domain Structure, this is the ontology for the domain as described in Section 1 (A Domain Ontology for an NL Querying System). The second is the "Domain Specific Linked Terms" Ontology. The purpose of this ontology is to allow the user to define related terms.
6.1. Wordnet
Wordnet is an online lexical database. One of the functions of a lexical database is to work like a thesaurus. If you query it with one word, it will give you one or more sets of words that it believes to be synonymous. The reason it may give you more than one set of words is because the word queried belongs to more than one lexical concept. A lexical concept is basically an idea, which can be expressed using one or more different words. In Wordnet, a lexical concept is the hub of the lexical database. Each lexical concept can have one of five types, noun, verb, adjective, adjective satellite and adverb. This lexical concept can then have one or more words as well as usually one but sometimes more than one definitions. One of the other major features of Wordnet is the linking of lexical concepts together. This is acheived using a number of different relationship, including antonym, hyponym, hypernym, meronym, holonym and several others. Being able to link lexical concepts together like this is particular useful, as it dramatically increases the amount of information that can be stored with very little effort. Hyponyms and hypernyms can generate hierarchical trees and so can meronyms and holonyms. This can aid a user in determining how synonymous two words are by how many leaps are required to get from one to another.
Wordnet was originally created a lexical database stored in a relational database model (i.e. SQL), however there have been several attempts to implement it so it can be used with Semantic Web knowledge technologies, i.e. RDF, OWL and triplestores. The University of Neuchâtel's knOWLer project has defined an ontology for Wordnet 1.7.1. Below is a diagram to represent this ontology. A key to all the symbols in the diagram can be found here.
{kind=link}
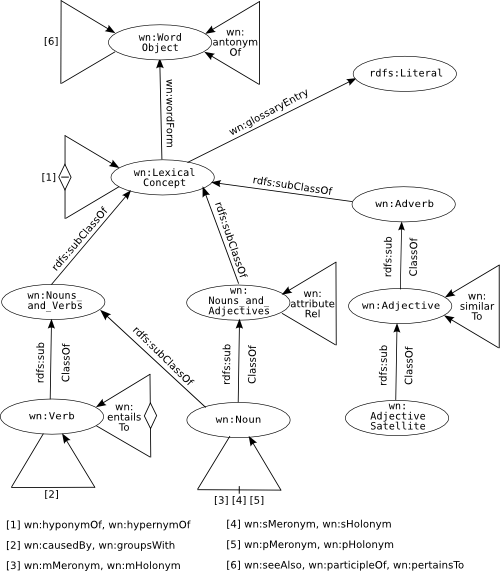
The W3C has recently publised a working draft for an RDF/OWL Representation for Wordnet, which is a bit more up to date as it was only published in June 2006.
6.2. Thesaurus Ontology
I have taken the Wordnet Ontology produced for the knOWLer project and adapted it to allow me to define user-specified thesauruses. This basically meets the original requirements that I set out for the "Domain Specific Linked Terms" Ontology, described in section 4 but I realised that the ontology could be more powerful than that. There was no reason that the ontology could be extended so it not only maps one lexical concept to another but it maps lexical concepts to concepts defined in an ontology for a particular domain. This would basically fulfil almost two components of my specification for an NL querying system in one go, i.e. the terminology standardisation and significant parts of the machine-readable query generation.
Below is a diagram of the ontology that I have designed that allows users to manage there own thesaurus user accounts
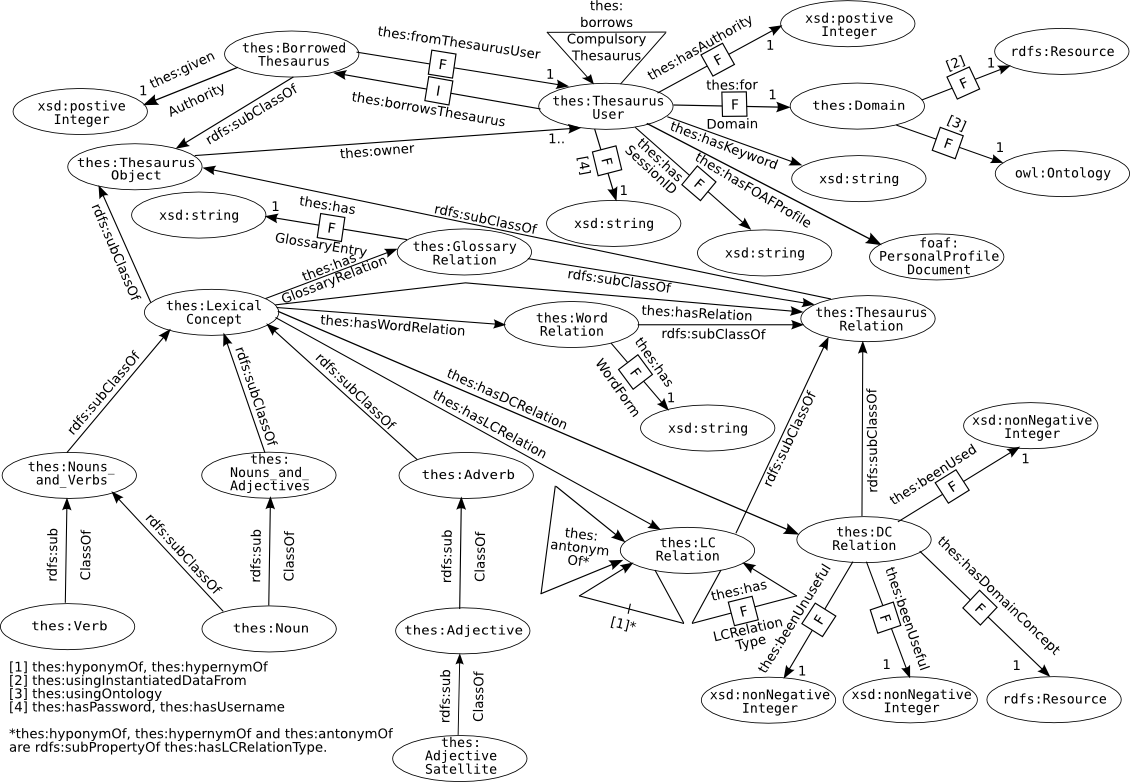
As you can see from the diagram above a significant chunk of the ontology is based on the Wordnet ontology. Currently only a couple of the relationships between lexical concepts have been adopted. This is because a lot of these relationships such as holonymOf and meronymOf are not going to be particularly useful when it comes to trying to map to a domain ontology specified concept (domain concepts). E.g. knowing that one lexical concept has a holonynmOf relationship with another lexical concept does not mean that you can them consider the domain concepts linked to that second lexical concept as being suitable mappings. This is not true with the hypernymOf and hyponymOf relationships because they are more likely to return mappings to plausible domain concepts.
There is a subtle relaxation from the wordnet ontology on the antonymOf relationship which now is applied to lexical concept relations rather than word obbjects. This basically means that all the words of one lexical concept can be considered antonyms of another lexical concepts, this may seem foolish as thiscould show two words as being antonym of each other despite the fact that they are used in completely different contexts. E.g. "win", is defined in a lexical concept with the word "gain", gain has an antonym which is "fall back", this would technically mean that an antonym of win is fall back. If you were then to take the sentence "I did not win" and you used an antonym so you could drop the not you would end up with "I did fall back". Clearly these two sentences do not mean the same thing. That said the purpose of the Thesaurus ontology is not to map from one word to another word, it is to determine the most likely domain concept mapping for a given word / lexical concept.
6.3. How to Measure a Mapping
How to determine which domain concept is most likely to be the correct mapping from a lexical concept is difficult. Currently the thesaurus ontology provides the ability to enforce a reinforcement learning algorithm to determine which mapping is the most likely. This algorithm uses three integer-typed properties associated with each domain concept relation instance, beenUsed, beenUseful and beenUnuseful. As the names might suggest, the first increments every time the NL querying system uses the domain concept relation, the second increments every time it is found to be the correct mapping and the last increments every time it is found to be the incorrect mapping. This begs the question how do you know when a mapping is correct and when it is incorrect, this clearly needs user input but it must be as discreet as possible as to not annoy the user. If the NL querying systems determines that there are several possible lexical to domain concept mappings then it will be able to use the three variables of the reinforcement learning algorithm to rank the mappings. Currently I plan to use the following formula to determine a mapping' rank:
Mapping Score = ( beenUseful + beenUsed - beenUnuseful ) / beenUsed
The reason why this particular formula has been chosen is to do with the way that beenUnuseful and beenUseful are to be incremented. When a result is returned to a user, he/she will also be prompted with two options, one is to acknowledge that the result is correct, the second is to state the result is incorrect and to try a different mapping if one exists. The inherent problem with this user interface is that a user is less likely to acknowledge that a result is correct as they will be too busy using that result. However, if the user does not get the correct answer there is a much higher probability they will acknowledge the incorrect result in hope of finding the correct result a second time. Through using the formula suggested above, instead of something more simple like beenUseful / beenUsed, it rewards beenUseful but it also rewards everything that is not beenUnuseful. This means that it rewards beenUseful twice. It may be necessary to tweak the formula once the system goes online to reward beenUseful slightly more or slightly less.
6.4. Thesaurus User Accounts
One of the main adaptations of the Wordnet ontology was to provide separate user accounts, so that users could have their own thesauruses. The diagram for the Thesaurus ontology shows that the main hub for this adaptation is the ThesaurusUser class. This class has a number of properties associated to it, (some directly and some indirectly), these serve three major purposes:
- To give information about the user account for purposes of login and identification, i.e. hasUsername, hasPassword, forDomain, hasFOAFProfile and hasKeyword. forDomain refers to the particular domain a user account is storing a thesaurus for, this property value is required at login because the same username may be used for different domains. hasFOAFProfile is a link to a FOAF Personal Profile Document, as a FOAF profile stores useful information about the user it is much quicker for the user to import their profile rather than entering lots of separate bits of data.
- To give information for the production of RDF/XML, i.e. usingOntology and usingInstantiatedDataFrom. These two properties tell the user the location of the ontology and the location of any folders that store instatiated data about the domain, that is to say semi-structural data such as a type for an album or a type of musical action (see section 1). Without this information it would be impossible to generate new RDF/XML models that can then be inported into the triplestore.
- To give information about thesaurus data the user borrows, i.e. borrowsThesaurus, borrowsCompulsoryThesaurus, fromThesaurusUser, hasAuthority and givenAuthority. There are two ways that a user can borrow a thesaurus, compulsorily and optionally. Compulsory thesauruses borrowing is user set up when the user account is created. Optionally thesauruses can be borrowed or dropped directly by the user. The main difference between the two types is that the authority value that a user must give to it must be the same as its hasAuthority value, whereas an optionally chosen thesauruses can have its authority value set by the user through the givenAuthority value.
When a new user account is created values must be set for hasUsername, hasPassword (which is MD5ed), hasAuthority and forDomain. Any compulsory thesauruses are also usually set at this point but there is no reason they cannot be added at a later date. Once the account is created the user may edit his/her account by adding/removing optionally borrowed thesauruses, FOAF profile and keywords.
One of the most difficult problems to solve with implementing user accounts is maintaining consistency. E.g. Imagine there is already one completed thesaurus with many lexical concepts with relations to glossary entries, word forms, domain concepts and other lexical concepts. If a new user borrows this thesaurus, then they will be able to use these concepts and relations but they will also be able to create their own relations from these lexical concepts and link borrowed lexical concepts with their own new lexical concepts. Using the owner property means each lexical concept, word, glossary, lexical and domain relation must be owned by at least one user but can be owned by many users. This property ensures that if any lexical concept or relation is deleted from one user's thesaurus it will not be removed from another user thesauruses if they are using it, i.e. has created relations from it. This still inevitably means that if a lexical concept is deleted from one user's thesaurus and the user that borrows it has not created any relations from it, the lexical concept will no longer exist for the borrowing user. Therefore it may become necessary for a user to permanently borrow lexical concepts or relations from another user's thesaurus but it would be wrong for a user to be allowed to permanently borrow everything from another thesaurus as changes made to this borrowed thesaurus may actually be corrections or useful modifications, which would be lost if another user has permanently borrowed everything.
The way that the owner property is used means that two users can own the same lexical concept or relation but be unaware of each other's ownership. This is because the system has been designed so the user is only made aware of other users that own a concept / relation if they are user's that they borrow thesauruses from. This may seem a bit odd but it is the most sensible approach as there is little benefit for user knowing this information as it will in no way effect them but if they are aware of the information, it may just confuse them.
6.5. Discovering Thesauruses
Potentially there could be tens if not hundreds of thesaurus user accounts for one domain. This creates a major headache, how does a user find thesauruses that might be useful to him/her. Giving a thesaurus user account a username that describes what the thesaurus is about, is neither very sensible nor sufficient. An appropriate username to describe the thesaurus will probably be long-winded and will cause hassle when the user has to login. Therefore the hasKeyword property has been defined so that a user can tag their thesaurus with appropriate keywords. This gives a very flexible way to mark up thesauruses but inevitably greater flexibility leads to lesser formality, meaning that unless a user can hit on the right keyword(s) they may not find the thesaurus that is most useful to them.
Other methods have been considered to try and improve thesaurus discovery, e.g. ISBN used in book numbering or the Dewey Decimal Classification (DDC) used in libraries. The problem with both of these systems is that there may well be thesauruses that cannot be defined under this system or can only be defined in a fairly convoluted way. Therefore again a user may not be able to find the right thesaurus for them.