


How to Write Good OWL Ontologies
In my experience of reviewing other ontologies, reading papers on OWL and writing my own ontologies, I have found some good design practices and some really quite bad ones. Therefore, in this blog I intend to set out good design practices for OWL ontologies and why I believe these to be better than some of the practices that I have found.
Contents
- 11/06/2007 Qualified Cardinality Restrictions: A New Feature of OWL 1.1
- 23/11/2006 REVIEW:- Putting OWL in Order: Patterns for Sequences in OWL
- The Vision of OWLLists
- When OWLLists get Large
- Unwanted Additional List Branches
- Circular Lists
- How Long is the List
- Pattern Matching in OWLLists
- What Classes are in my List
- Conclusion
- 10/11/2006 OWL Doesn't like RDF:Bag and RDF:Seq
- 29/09/2006 Defining Properties in OWL
- 28/09/2006 Defining XML Entities for your Namespaces
- 27/09/2006 Different Species of OWL
Entries
<< Previous Entry | Next Entry >>
10/11/2006 OWL Doesn't like RDF:Bag and RDF:Seq
In my earlier blog, Different Species of OWL, I talked about how some ontologies are OWL Full when they really could be OWL DL. I mentioned several reason for why this occurred and tried to explain how they could be resolved. One of these reasons was the use of RDF:Bag and RDF:Seq that are prohibited in OWL DL. I don't believe I did justice on explaining how using them could be avoided without losing too much of their expressiveness, so I thought I would have a nother go.
RDF:Bag is the easier of these two constructs to handle. As mentioned before RDF:Bag is basically an unordered list. In the MusicBrainz Ontology it is used three times to store lists for albums, CD index ids and trmids. The advantage of using a property that maps between an object and a list that the maximum cardinality of the relationship can be set to one making it a binary relationships, e.g. a track either has a list of trmids associated to it or not. This insurance that you have all of the available data for a particular type of relationship is useful but because the Open World Assumption (OWA) must still be observed you cannot be certain that all the available data is actually the complete data. Therefore the merits of RDF:Bag are limited, it could be said that using lists means that a search algorithm only has to find one relationship rather than many but the way that many triplestores are indexed finding one triple with a certain subject and predicate takes about as long as finding several. RDF:Bag does not actually restrict the type of objects it contains meaning that a track list contain a set of uris for artists. Having relationships between the original subject and all the individual objects of the list would actually prevent this from happening, which can only be beneficial and is the most sensible way of dealing with RDF:Bag.
RDF:Seq is basically and ordered list, this means it more difficult to resolve down to OWL DL. The main difficulty is how to maintain the order of the list. There are several ways of acheiving this. A rather dirty but quick way of solving the problem is to almost the same as you would for RDF:Bag but reify the relationships between the subjects and the item of the ordered list to store the position in the list as an XML Schema integer and store that in an object that represents the relationship between the original subject and one of the objects of the ordered list. A slight variation on this could be to create an additional property for the object so that it can store what position it would have had in the list as an integer. This is an adequate way of solving the problem if the list is unlikely to change. E.g. a numbered list of tracks on album is a perfect case for using this as tracks generally have numbers associated with them any way. Below is diagram explaining the subtle difference between these two techniques.
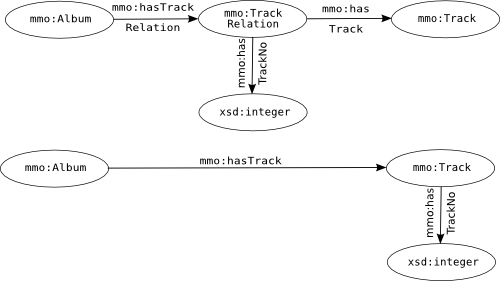
There is a slight advantage to using the first approach over the second. Take the example of tracks on an album. Two albums may have the same track but at different position in the album, the first approach only requires you to create a new TrackRelation, this contains minimal information, (a track number and a uri), whereas the second approach would require you creating a whole new track object, this would mean that you would have two track objects that to all intents and purposes represent the same track, which is wasteful and can lead to inconsistencies as well as confusion. In My Music Ontology (MMO) although it may look as though I have used the second approach, I have actually considered which compoenents of a track which cannot change between album, i.e. basically only the track's name and that has been made a property of track whereas things that can change between albums, i.e. a track's duration and number are part of track instance, for which a new object is created for every track on every album.
I have recently read a paper that talk about OwlLists. These lists are attempt to provide the same sort of expresiveness that RDF:Bag and RDF:Seq provide but with the ability to reason over them using a DL reasoner, i.e. allowing a user to design an ontology that uses lists but is still OWL DL compliant. In my next blog I will discuss my thoughts on this paper.